오늘은 사이킷런에서 제공하는 kneighborsregressior 클래스의 score 메소드에 대해 설명하겠습니다.
우선 k-최근접 이웃 알고리즘의 회귀 버전 kneighborsregressior은,
입력 데이터에 대한 예측값을 만들기 위해서 가장 가까운 이웃 샘플을 찾고 이 샘플들의 타깃값의 평균을 계산하는 알고리즘입니다.
kneighborsregressior 클래스의 score 메소드는 예측한 값의 품질을 평가하는 데 사용됩니다. 0과 1사이의 값을 가지는 결정 계수 R2 값을 반환하는데요.
R2 값이 1에 가까울수록 모델의 예측이 실제 데이터를 잘 설명한다는 의미이고, 0에 가까울수록 모델의 예측 성능이 좋지 않음을 의미합니다.
R2 계산 방법은 다음과 같습니다.
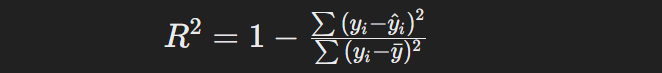
여기서 yi는 타깃값, y^i는 예측값이며, yˉ 는 타깃 평균값을 의미합니다.
결정 계수를 구하는 식을 좀 더 간단히 설명드리겠습니다. 우선 타깃값에서 예측값을 뺀 값을 제곱하여 다 더한 후, 타깃값에서 타깃 평균값을 뺀 값을 제곱하여 다 더한 값으로 나눕니다. 그 값을 1에서 제하면 됩니다.
* kneighborsregressior 의 score를 사용하는 간단한 예시입니다.
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
from sklearn.datasets import make_regression
...
#객체 생성
model = KNeighborsRegressor(n_neighbors=5)
#훈련
model.fit(X_train, y_train)
...
#모델 성능 평가
score = model.score(X_test, y_test)
print("R^2 Score:", score)
예시에서 X-train, y_train 데이터를 생성하는 과정은 생략하였습니다. 하지만 훈련된 model 객체를 가지고 score를 어떻게 활용하는지는 확인할 수 있습니다.
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsRegressor.html
sklearn.neighbors.KNeighborsRegressor
Examples using sklearn.neighbors.KNeighborsRegressor: Face completion with a multi-output estimators Imputing missing values with variants of IterativeImputer Nearest Neighbors regression
scikit-learn.org
'AI > 관련 자료' 카테고리의 다른 글
| 머신러닝 알고리즘 선택 기본 가이드 (1) | 2024.11.04 |
|---|---|
| 그리드 서치와 랜덤 서치 (Grid Search & Random Search) (0) | 2024.11.01 |
| [Youtube] What is LSTM (Long Short Term Memory) (4) | 2024.10.07 |
| [Numpy] 사이킷런 train_test_split()으로 훈련 세트와 테스트 세트 분리하기. (0) | 2024.02.15 |
| [머신러닝/ML] 머신 러닝 기초 - 1 (개념과 예시) (0) | 2023.02.15 |

