[혼공머신] 06-3 | 주성분 분석
키워드
차원 축소
차원 축소는 원본 데이터의 특성을 적은 수의 새로운 특성으로 변환하는 비지도 학습의 한 종류이다. 차원 축소는 저장 공간을 줄이고 시각화하기 쉽다. 또한 다른 알고리즘의 성능을 높일 수도 있다.
주성분 분석
주성분 분석은 차원 축소 알고리즘의 하나로 데이터에서 가장 분산이 큰 방향을 찾는 방법이다. 이런 방향을 주성분이라고 부른다. 원본 데이터를 주성분에 투영하여 새로운 특성을 만들 수 있다. 일반적으로 주성분은 원본 데이터에 있는 특성 개수보다 작다.
설명된 분산
설명된 분산은 주성분 분석에서 주성분이 얼마나 원본 데이터의 분산을 잘 나타내는지 기록한 것이다. 사이킷런의 PCA클래스는 주성분 개수나 설명된 분산의 비율을 지정하여 주성분 분석을 수행할 수 있다.
핵심 패키지와 함수
scikit-learn
PCA
- 주성분 분석을 수행하는 클래스이다.
- n_components는 주성분의 개수를 지정한다. 기본값은 None으로 샘플 개수와 특성 개수 중에 작은 것의 값을 사용한다.
- random_state에는 넘파이 난수 시드 값을 지정할 수 있다.
- components_ 속성에는 훈련 세트에서 찾은 주성분이 저장된다.
- explained_variance_ 속성에는 설명된 분산이 저장되고, explained_variance_ratio_ 에는 설명된 분산의 비율이 저장된다.
- inverse_transform() 메서드는 transform() 메서드로 차원을 축소시킨 데이터를 다시 원본 차원으로 복원한다.
06-3 단원 내용
시작하기 전에
나중에 군집이나 분류에 영향을 끼치지 않으면서 업로드된 수많은 사진의 용량을 줄일 수 있을까?
차원과 차원 축소
데이터가 가진 속성을 특성이라고 부른다. 과일 사진의 경우 10,000개의 픽셀이 있기 때문에 10,000개의 특성이 있다고 볼 수 있다. 머신 러닝에서는 이런 특성을 차원dimension이라고도 부른다.
차원을 줄일 수 있다면 저장 공간을 크게 절약할 수 있다. 이를 위해 비지도 학습 작업 중 하나인 차원 축소dimensionality reduction 알고리즘을 다루어 보자. 차원 축소는 데이터를 가장 잘 나타내는 일부 특성을 선택하여 데이터 크기를 줄이고 지도 학습 모델의 성능을 향상시킬 수 있는 방법이다.
주성분 분석 소개
주성분 분석PCA는 데이터에 있는 분산이 큰 방향을 찾는 것으로 이해할 수 있다. 이 벡터를 주성분principal component라고 부른다. 주성분 벡터는 원본 데이터에 있는 어떤 방향이다. 주성분 벡터의 원소 개수는 원본 데이터셋에 있는 특성 개수와 같다.
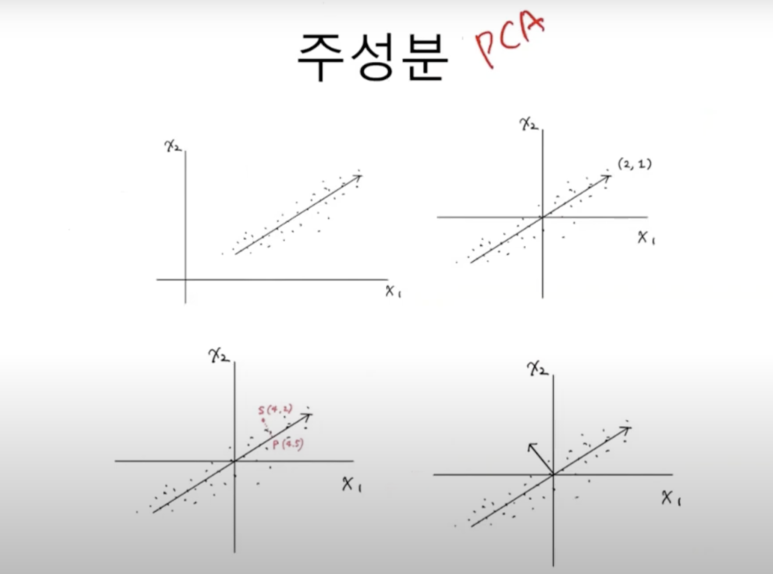
주성분은 원본 차원과 같고, 주성분으로 바꾼 데이터는 차원이 줄어든다는 점을 꼭 기억하자.
PCA 클래스
과일 사진 데이터를 다운로드하여 넘파이 배열로 적재하기
!wget https://bit.ly/fruits_300_data -0 fruits_300.npy
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)
PCA 객체로 주성분 찾기
from sklearn.decomposition import PCA
pca = PCA(n_components=50)
pca.fit(fruits_2d)
components_ 속성 배열 크기 확인하기
print(pca.components_.shape)
# (50, 10000)
# 50개의 주성분을 찾았으며,
# 두 번째 차원은 항상 원본 데이터의 특성 개수와 같은 10,000
주성분을 그림으로 그려보기
draw_fruits(pca.components_.reshape(-1, 100, 100))
transform()을 활용해 원본 데이터의 차원 줄이기
print(fruits_2d.shape)
# (300, 10000)
fruits_pca = pca.transform(fruits_2d)
print(fruits_pca.shape)
# (300, 50)
원본 데이터 재구성
앞서 최대한 분산이 큰 방향으로 데이터를 투영했기 때문에, 원본 데이터를 상당 부분 재구성할 수 있다.
50개의 차원으로 축소한 데이터로 10,000개의 특성을 복원하기
fruits_inverse = pca.inverse_transform(fruits_pca)
print(fruits_inverse.shape)
# (300, 10000)
10000개의 특성이 복원된 데이터를 100*100 크기로 바꾸어 100개씩 나누어 출력하기
fruits_reconstruct = fruits_inverse.reshape(-1, 100, 100)
for start in [0, 100, 200] :
draw_fruits(fruits_reconstruct[start:start+100])
print("\n")

거의 모든 과일이 잘 복원되었음을 확인할 수 있음.
설명된 분산
주성분이 원본 데이터의 분산을 얼마나 잘 나타내는지 기록한 값을 설명된 분산explained variance이라고 한다.
PCA클래스의 explained_variance_ratio_에 각 주성분의 설명된 분산 비율이 기록되어 있다.
print(np.sum(pca.explained_variance_ratio_))
"""
0.9215... -> 92퍼센트가 넘는 분산으로,
앞에서 50개의 특성에서 원본 데이터를 복원했을 때
원본 이미지의 품질이 높았던 이유를 찾을 수 있음.
"""
설명된 분산의 비율을 그래프로 그려보기
plt.plot(pca.explained_variance_ratio_)
plt.show()
다른 알고리즘과 함께 사용하기
과일 사진 원본 데이터와 PCA로 축소한 데이터를 지도 학습에 적용해 보고, 어떤 차이가 있는지 알아보자.
*로지스틱 회귀모델과 함께 사용하기
1. 사이킷런 LogisticRegression모델 만들기
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
2. 타깃값 만들기
target = np.array([0]*100 + [1]*100 + [2]*100)
3. 원본 데이터로 교차 검증 해보기
from sklearn.model_selection import cross_validate
scores = cross_validate(lr, fruits_2d, target)
print(np.mean(scores['test_score']))
print(np.mean(scores['fit_time']))
# 0.99...
# 0.94...
4. PCA로 축소한 데이터로 교차 검증 해보기
scores = cross_validate(lr, fruits_pca, target)
print(np.mean(scores['test_score']))
print(np.mean(scores['fit_time']))
"""
1.0 0.03
-> 50개의 특성만 사용했는데도 정확도는 100%, 훈련 시간은 20배 이상 감소함.
"""
*PCA클래스의 n_components 매개변수에 주성분의 개수 뿐만 아니라 설명된 분산의 비율을 입력할 수도 있다.
1. 설명된 분산의 50%에 달하는 주성분을 찾도록 PCA모델 만들어보기
pca = PCA(n_components=0.5)
pca.fit(fruits_2d)
print(pca.n_components_)
#2개의 주성분을 찾음 단 2개의 특성만으로 원본 데이터에 있는 분산의 50%를 표현할 수 있다는 뜻
2. 주성분 2개의 모델로 원본 데이터 변환하기
fruits_pca = pca.transform(fruits_2d)
print(fruits_pca.shape)
# (300,2)
3. 2개의 특성만 사용한 데이터로 교차 검증 결과 확인하기
scores = cross_validate(lr, fruits_pca, target)
print(np.mean(scores['test_score']))
print(np.mean(scores['fit_time']))
"""
0.99... 0.04...
-> 2개의 특성을 사용했을 뿐인데 99%의 정확도 달성
"""
* K-평균 알고리즘과 함께 사용하기
1. 차원 축소된 데이터를 활용해 K-평균 알고리즘으로 클러스터 찾기
from sklearn.cluster import KMeans
km = KMeans(n_cluster=3, random_state=42)
km.fit(fruits_pca)
print(np.unique(km.labels_, return_counts=True))
"""
(array([0,1,2], dtype=int32), array([100, 99, 91])
"""
2. KMeans가 찾은 레이블을 사용해 과일 이미지 출력하기
for label in range(0,3) :
draw_fruits(fruits[km.labels_ == label])
print("\n")
3. 2개의 특성을 가진 fruits_pca데이터로 산점도 그려보기
for label in range(0,3) :
data = fruits_pca[km.labels_ == label]
plt.scatter(data[:,0], data[:,1])
plt.legend(['apple', 'banana', 'pineapple'])
plt.show()
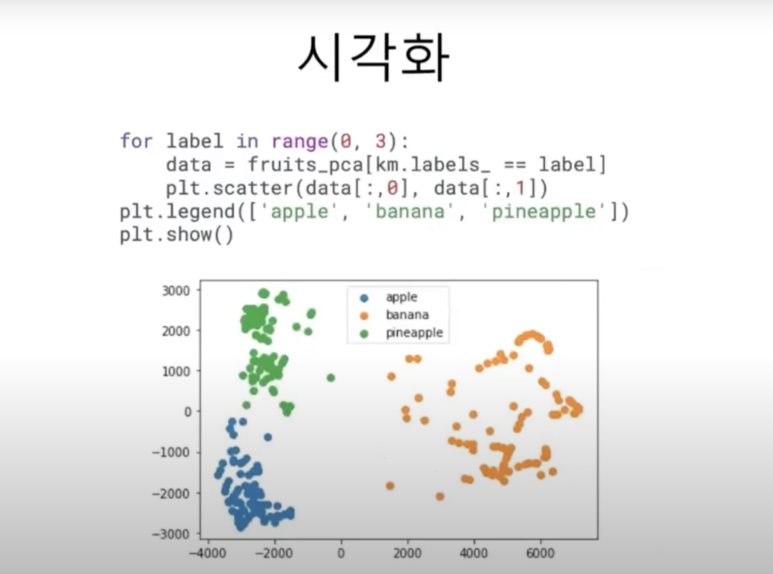
주성분 분석으로 차원 축소